25 KiB
数据库原理实验大作业报告
实验选题简介
本次大作业中,我选择实现的是一个电子书管理系统。设计初衷是为我自己的服务器和几千本电子书写一个可控、可定制的电子书存储和索引服务程序。其主要功能为存储和管理电子书及其相应的文档数据,用户可以上传电子书到服务器上存储、从服务器上搜索并下载自己的电子书。为了迎合本次实验的要求,还为该系统提供了用户登陆控制功能。
数据库设计
需求分析
用户需求分析
**主要面向用户:**有轻量级云端个人电子书存取需求的用户,比如我
**数据需求:**图书信息、电子书文件信息、服务器统计信息
**功能需求:**1. 上传、存储或删除电子书,具有不同副本管理的功能,同时需要有历史记录来追溯漏洞;2. 搜索并下载电子书;3. 对电子书的进行分类管理,如按照标签、作者、出版社等;4. 可以在电子书上附加评论或注释;5. 多用户和管理员功能。
数据字典-数据处理
- 处理过程名:用户管理 说明:管理员对用户信息进行基本的CRUD操作 输入:CRUD请求、用户基本信息 输出:D1中的用户信息记录
- 处理过程名:图书管理 说明:用户新建、修改、查询、删除图书数据 输入:请求、用户身份、图书数据 输出:D2图书信息
- 处理过程名:存储管理 说明:从其他处理过程中接收数据和请求,实际操作电子书在服务器上的存放 输入:D2的图书编号、D1的用户身份、存取操作 输出:D3存储信息
- 处理过程名:上传下载管理 说明:用户对指定的文档进行上传和下载 输入:电子文档的文件属性数据、用户的操作请求 输出:D5存取记录、存取操作
- 处理过程名:笔记管理 说明:用户在特定的书籍上添加和查看笔记 输入:用户请求、D1用户身份、D2图书编号 输出:D4中的笔记记录
- 处理过程名:分类信息维护 说明:在添加书籍时,维护分类和作者信息,方便统计查询 输入:电子文档的图书数据 输出:D6、D7
数据字典-数据流
-
数据流名:管理数据
说明:管理员验证身份,建立用户档案
来源去向:管理员 -> P1
数据结构: 密码+用户信息表
-
数据流名:用户身份
说明:不同的用户身份进入的处理过程不同。
来源去向:P1->P2.1 P1->P2.2
数据结构: 用户信息表
-
数据流名:查询请求
说明:通过书名和类别查询库中的图书
来源去向:用户 -> P2.1
数据结构: 类别/书名,图书信息表
-
数据流名:图书数据
说明:根据电子文档对应的图书情况新建图书记录
来源去向:图书 -> P2.1,图书 -> P2.3
数据结构: 图书信息表
-
数据流名:文件数据
说明:上传文件时,需要提供文件的属性
来源去向:电子文档 -> P3
数据结构: 文件属性表
-
数据流名:存取情况
说明:提供存取操作的数据封装,完成实际的数据存取
来源去向:P3 -> P2.2
数据结构: 存取操作结构
-
数据流名:图书编号
说明:通过图书编号来识别和每种图书相关的数据
来源去向:P2.1->P4, P2.1->P2.2
数据结构: 类别/书名,图书信息表
-
数据流名:笔记请求
说明:通过图书编号发起添加或者查看笔记的请求。
来源去向:用户 -> P4
数据结构: 图书编号,笔记信息
数据字典-数据存储
-
数据存储名:用户信息
说明:存放注册用户的相关信息,邮箱需要唯一
编号:D1
组成:用户编号,用户名,用户邮箱,用户密码,用户空间占用,用户配额,注册日期
数据量:不多于10条
存取频度:每天100次
存取方式:随机检索为主
-
数据存储名:图书信息
说明:电子书的出版相关的信息,ISBN唯一,不包括实际的电子书文档信息
编号:D2
组成:编号,ISBN,出版社,类型,作者,日期,语言
数据量:500条左右
存取频度:每天200次
存取方式:随机检索和更新
-
数据存储名:存储信息
说明:电子书文档的相关数据,和图书信息密切相关
编号:D3
组成:副本编号,资源URL,大小,日期
数据量:800条左右
存取频度:每天300次
存取方式:随机检索为主
-
数据存储名:笔记信息
说明:读者对图书发表的笔记和注解
编号:D4
组成:编号,日期,内容
数据量:1600条左右
存取频度:每天300次
存取方式:随机检索和插入
-
数据存储名:存取记录
说明:记录电子书文档的上传、下载和删除,方便统计和故障查询
编号:D5
组成:图书副本编号,用户编号,操作类型,日期
数据量:2000条左右
存取频度:每天300次
存取方式:主要是按照时间顺序插入,有时会有全表统计查询
-
数据存储名:类型信息
说明:记录图书的类型,方便统计和查询
编号:D6
组成:类型编号,类型名称
数据量:200条左右
存取频度:每天100次
存取方式:随机CRUD
-
数据存储名:作者信息
说明:记录图书的作者,方便统计和查询
编号:D7
组成:作者编号,作者姓名
数据量:200条左右
存取频度:每天100次
存取方式:随机CRUD
数据流图

概念结构设计
实体分析
**实体:**管理员、用户、图书、文件、笔记、类型、作者
语义描述:
- 一个系统里面有多个相互独立的用户,用户拥有多个图书,图书可以对应多个版本的文件,图书可以有多个笔记。一个文件只能对应一本图书。
- 系统只有一个管理员,管理员不是用户,只有操作用户账户的权限,不具有对其他信息进行操作的权限。
- 一个用户只能管理自己所拥有的图书、文件和笔记
- 用户有存储空间配额的限制,上传的文件不能超过配额。
- 一本图书可以被分到多个类别里面,一个类里面有多本书;一本书可以有多个作者,一个作者可以写多本书
E-R图
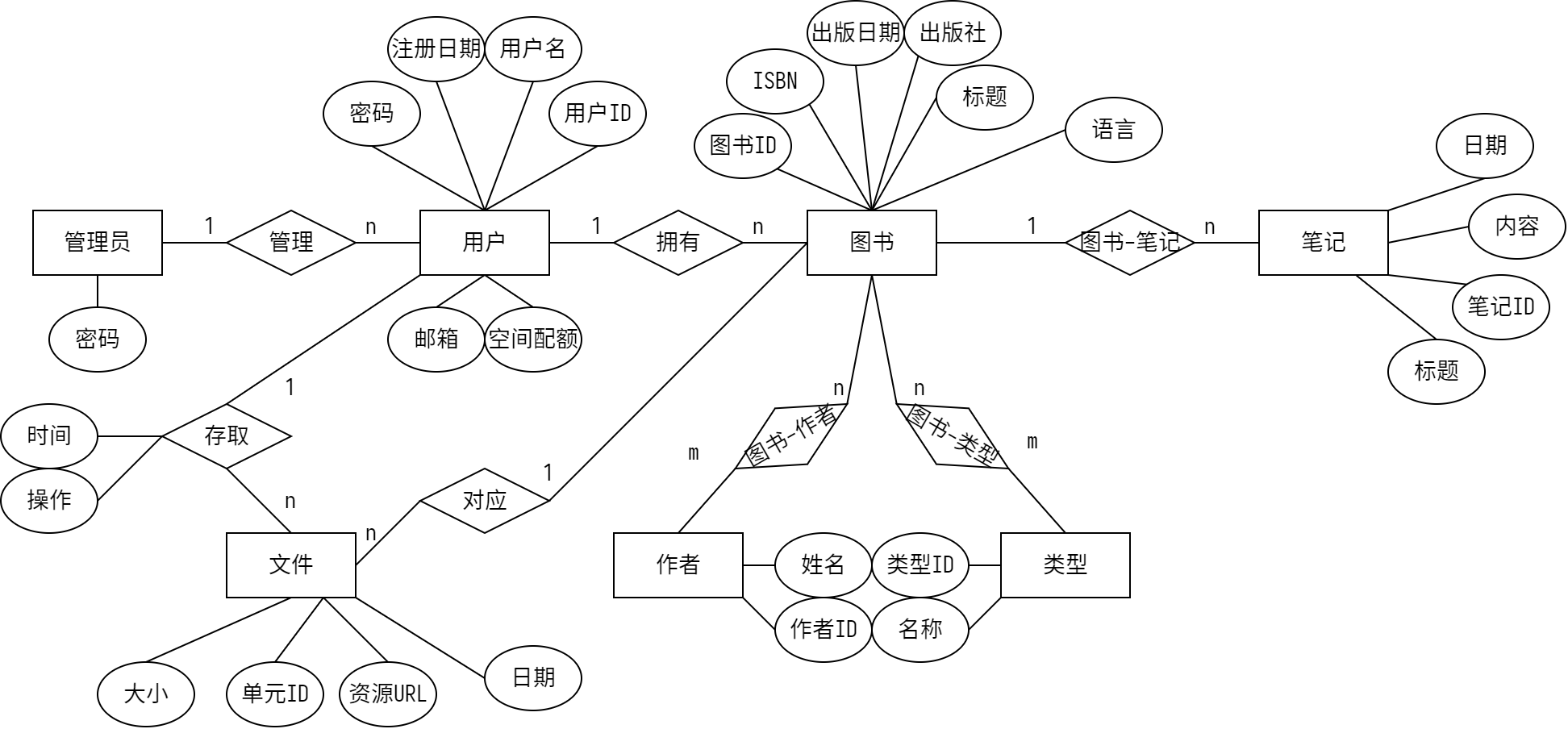
逻辑结构设计
转换关系
实体转换:
-
管理员:admin(密码)
系统中只有一个管理员,密码只能通过直接操作数据库修改,这仅作为一个存储项,也不需要主键之类的东西。
-
用户:user(用户ID, 用户名, 用户邮箱, 用户密码, 用户配额, 注册日期)
-
图书:book(图书ID,ISBN,出版社,日期,语言,标题)
-
文件:document(文件ID,资源URL,大小,日期,类型,副本名)
-
笔记:note(笔记ID,日期,内容,标题)
-
类型:type(类型ID, 类型名称)
-
作者:author(作者ID, 作者姓名)
联系转换:
- 管理:管理不直接通过数据表体现,因此不需要添加任何的关系。
- 拥有:一对多关系,因此在图书里面添加外键用户ID,修改图书关系为book(图书ID,用户ID(FK ref user),ISBN,出版社,日期,语言, 标题)
- 存取:一对多关系,但是由于该联系有自己的属性,所有单独新建一个关系 record(记录ID,时间,操作类型,用户ID,文件URL)。由于这里可能涉及到删除操作,因此使用外键,仅保留存取记录。
- 对应:一对多关系,直接在文件里面添加外键图书ID,修改文件关系为document(文件ID,图书ID(FK ref book),资源URL,大小,日期)
- 图书-笔记:一对多关系,直接在笔记关系中增加外键,修改关系为note(笔记ID,图书ID(FK ref book),日期,内容)
- 图书-作者:多对多关系,单独建立一个关系book_author(图书ID(FK ref book),作者ID(FK ref author))
- 图书-类型:多对多关系,单独建立一个关系book_type(图书ID(FK ref book),类型ID(FK ref type))
关系模式优化
book_author、book_type两个为全码,无非主属性,必然满足BCNF
其余关系的函数依赖集如下:
- type:
{类型ID->类型名称} - author:
{作者ID->作者姓名} - user:
{用户ID->用户名, 用户ID->用户邮箱, 用户ID->用户密码, 用户ID->用户配额, 用户ID->注册日期} - book:
{图书ID->用户ID, 图书ID->ISBN, 图书ID->出版社, 图书ID->日期, 图书ID->语言, 图书ID->标题} - document:
{文件ID->图书ID, 文件ID->资源URL, 文件ID->大小, 文件ID->日期} - note:
{笔记ID->图书ID, 笔记ID->日期, 笔记ID->内容, 笔记ID->标题} - record:
{记录ID->用户ID, 记录ID->操作类型, 记录ID->时间, 记录ID->文件URL}
可以看出,他们均为非主属性对码的完全函数依赖,满足BCNF。
其他优化
冗余设计:
- 因为用户可能会经常需要看自己发布的笔记,虽然可以通过先查book表再查note,但是这样会降低查询效率,因此在note关系中添加用户ID。对于document也需要做同样的冗余属性列的添加,以提高某些情况下的查询效率。
- 建立一个用户的统计数据表,里面存放了用户占用的存储空间、创建的图书数量、种类等信息,可以减少查询时的数据库压力。
安全性设计:
- 数据加密:用户的密码通过sha256的方式存储在数据库中
- SQL注入:交给框架来完成
完整性约束:
- 用户占用的存储空间不能超过配额,也就是用户的文件关系中,文件大小属性之和不能大于用户的配额。
- 用户名和用户邮箱均可用来登陆,因此需要保证唯一性
触发器:
- 新建用户时,自动插入用户统计信息
- 上传和删除文件时,自动统计占用空间
- 增加图书的标签时,自动插入标签表中不存在的记录
物理设计
存储结构
- 存放位置为本地
- 存储结构为单机关系型数据库MySQL InnoDB,电子书文件存放在磁盘文件系统上
数据存取
- 对于type、author、user这三个表而言,一般只需要通过ID查询,因此无需建立额外的索引优化,直接用主键索引即可。book_author、book_type这两个全码表更是如此。
- 对于book、document、note、record有对于非主属性的联合和范围查询的需求,主要是对对于类型、作者等属性的联合查询。其中,对于范围较小的属性,如图书的语言、出版社、类型等属性,可以不建立索引。对于标题、日期等范围较大的索引,根据启发式规则建立相应的索引。
数据库实现
表设计
user
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| user_id | int | N | PK | AUTO_INC | 用户主键ID | |
| user_name | varchar | 200 | N | UNI | / | 用户名 |
| user_mail | varchar | 200 | N | UNI | / | 用户邮箱 |
| user_passwd | varchar | 200 | N | / | 用户密码 | |
| user_limit | int | N | / | 存储空间配额(KB) | ||
| user_regtime | timestamp | N | CURRENT_TIMESTAMP | 注册时间 |
book
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| book_id | int | N | PK | AUTO_INC | 图书主键ID | |
| book_name | varchar | 200 | N | INDEX | / | 标题 |
| book_isbn | varchar | 200 | Y | NULL | isbn号 | |
| book_publisher | varchar | 200 | Y | NULL | 出版社 | |
| book_lang | varchar | 20 | Y | NULL | 语言 | |
| user_id | int | N | FK | / | 所属用户 | |
| book_author | varchar | 1000 | Y | NULL | 书籍作者,默认用英文逗号分隔 |
document
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| doc_id | int | N | PK | AUTO_INC | 文档主键ID | |
| doc_name | varchar | 100 | N | INDEX | / | 文档名称 |
| doc_URL | varchar | 100 | N | / | 文档存储URL | |
| doc_size | int | N | 0 | 文档大小(KB) | ||
| doc_date | timestamp | N | CURRENT_TIMESTAMP | 上传日期 | ||
| doc_type | varchar | 100 | N | / | 文档类型 | |
| book_id | int | N | FK | / | 所属的图书id | |
| user_id | int | N | FK | / | 所属的用户id |
note
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| note_id | int | N | PK | AUTO_INC | 笔记主键ID | |
| note_name | varchar | 200 | N | INDEX | / | 笔记标题 |
| note_date | timestamp | N | CURRENT_TIMESTAMP | 笔记日期 | ||
| note_content | text | N | / | 笔记内容 | ||
| book_id | int | N | FK | / | 所属的图书id | |
| user_id | int | N | FK | / | 所属的用户id |
record
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| record_time | timestamp | N | PK | CURRENT_TIMESTAMP | 记录主键ID | |
| record_type | varchar | 10 | N | / | 操作类型 | |
| doc_URL | varchar | 200 | N | / | 被操作文件的URL | |
| user_id | int | N | / | 操作的用户id |
typetable
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| type_id | int | N | PK | AUTO_INC | 类型主键ID | |
| type_name | varchar | 20 | N | UNI | / | 类型名称 |
author
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| author_id | int | N | PK | AUTO_INC | 作者主键ID | |
| author_name | varchar | 100 | N | UNI | / | 作者名称 |
book_author
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| author_id | int | N | PK,FK | / | 作者主键ID | |
| book_id | int | N | PK,FK | / | 图书主键ID |
book_type
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| type_id | int | N | PK,FK | / | 类型主键ID | |
| book_id | int | N | PK,FK | / | 图书主键ID |
user_stat
| 字段名 | 数据类型 | 长度 | 可空 | Key | 默认值 | 含义 |
|---|---|---|---|---|---|---|
| user_id | int | N | PK | / | 用户主键ID | |
| user_usedspace | int | N | 0 | 占用的空间 | ||
| user_bookcount | int | N | 0 | 图书总数 | ||
| user_doccount | int | N | 0 | 文档总数 | ||
| user_notecount | int | N | 0 | 笔记统计 | ||
| user_limit | int | N | 0 | 由于数据库限制而复制的limit |
视图
由于 图书-分类 以及 图书-作者 这两对联系是多对多联系,因此需要分三张表存储,在应用程序编程时,需要写很长的SQL语句,比较不方便。因此建立根据图书ID查询类型ID、根据类型ID查询图书ID的两个视图,方便应用程序编写查询语句。下面是book和type的转换视图,book和author的转换同理,就不再列举了。
create view `v_book_to_types` as
select book_id, typetable.type_id as type_id, type_name
from book_type natural join typetable;
create view `v_type_to_book` as
select book_id, book_name,book_isbn,book_publisher,book_lang,
book_author,user_id,type_id,type_name
from book natural join book_type natural join typetable;
数据库端程序
触发器
在该项目中,使用四组触发器来实现以下功能:在新建和删除用户的时候自动维护统计信息表条目,在新建笔记、上传文件、新建图书的时候,自动维护统计信息表中的数据。
create trigger `trig_create_user_stat` after insert on user for each row begin
insert into user_stat (`user_id`, `user_limit`) values(NEW.user_id, NEW.user_limit);
end ##
create trigger `trig_delete_user_stat` after delete on user for each row begin
delete from user_stat where user_id=OLD.user_id;
end ##
create trigger `trig_update_stat_book_ins` after insert on book for each row begin
update user_stat set user_bookcount=user_bookcount+1 where user_stat.user_id=NEW.user_id;
end ##
create trigger `trig_update_stat_book_del` after delete on book for each row begin
update user_stat set user_bookcount=user_bookcount-1 where user_stat.user_id=OLD.user_id;
end ##
create trigger `trig_update_stat_doc_ins` after insert on document for each row begin
update user_stat set user_doccount=user_doccount+1 where user_stat.user_id=NEW.user_id;
update user_stat set user_usedspace=user_usedspace+NEW.doc_size where user_stat.user_id=NEW.user_id;
end ##
create trigger `trig_update_stat_doc_del` after delete on document for each row begin
update user_stat set user_doccount=user_doccount-1 where user_stat.user_id=OLD.user_id;
update user_stat set user_usedspace=user_usedspace-OLD.doc_size where user_stat.user_id=OLD.user_id;
end ##
create trigger `trig_update_stat_note_ins` after insert on note for each row begin
update user_stat set user_notecount=user_notecount+1 where user_stat.user_id=NEW.user_id;
end ##
create trigger `trig_update_stat_note_del` after delete on note for each row begin
update user_stat set user_notecount=user_notecount-1 where user_stat.user_id=OLD.user_id;
end ##
存储过程
- 在删除用户时,需要同时将该用户创建的标签一同删除,这个过程在客户端实现起来需要经过多条SQL语句才能完成,效率较低。因此将这个操作写成存储过程,在数据库端实现。
create procedure `clean_up_type_author`(in uid_in int) begin
declare done boolean default false;
declare v_bookid int;
declare cur cursor for select distinct book_id from book where book.user_id = uid_in;
declare continue handler for not found set done=true;
open cur;
mainloop: loop
fetch cur into v_bookid;
if done then
leave mainloop;
end if;
delete from typetable where type_id in (select type_id from book_type where book_id=v_bookid);
delete from book_type where book_id = v_bookid;
end loop;
close cur;
end ##
- 在给图书添加标签分类信息的时候,一般能够获得的数据是图书的编号和分类的名称,但是无法确定该分类是否存在。因此需要写一个根据分类名自动新建不存在分类并将相应数据插入type表和book-type表中。同样的,在客户端完成这一操作需要多条SQL语句,显得十分的不方便,故而写为存储过程。
create procedure `add_new_book_type`(in bookid_in int, in typename_in varchar(200)) begin
declare isnewtype int default 0;
declare isduplicated int default 0;
declare v_typeid int;
select count(type_name) into isnewtype from typetable where type_name=typename_in;
if isnewtype=0 then
insert into typetable (`type_name`) values (typename_in);
end if;
select type_id into v_typeid from typetable where type_name = typename_in;
select count(book_id) into isduplicated from book_type where type_id=v_typeid and book_id=bookid_in;
if isduplicated=0 then
insert into book_type (`type_id`,`book_id`) values (v_typeid, bookid_in);
end if;
end ##
程序设计
开发环境
- 操作系统:Windows10 22H2
- 语言:Python3.10、HTML+CSS+JavaScript
- 数据库:MySQL 8.0.30
- 工具框架:服务器端为Flask框架+jinja2模板引擎,数据库驱动为PyMySQL;客户端为Web,界面框架为spectre.css。
程序结构简述
服务程序功能模块划分如下图所示:

前端界面的操作逻辑主要分为两个部分:管理员界面,用来新建、删除和查询用户;用户界面,用来查询图书、上传下载电子书文档。可以用过程图简单描述如下:

问题及解决方法
-
SQLite3和MySQL迁移
在最开始的时候,为了方便程序的部署,我的程序使用SQLite3作为数据库。但非常不幸的是,老师禁止使用SQLite,因此我不得不将适配了SQLite3的代码迁移到MySQL上。这里遇到了几方面的问题:
- SQLite3语法和MySQL不完全兼容,在数据类型、默认值关键字、存储过程、索引和约束等方面均和MySQL有一定的区别,需要对比两者文档来迁移。
- pymysql库的接口不完全遵循Python的数据库驱动规范,存在部分功能缺失、相同接口语义不同的问题,需要重新编写这部分的代码
- pymysql没有SQL脚本执行功能,且无法一次执行多条SQL语句,因此难以直接用python代码初始化数据库,需要手工导入或编写专用的读取代码。
-
数据库自动初始化
我希望能够实现不需要用户手动导入SQL脚本就可以完成数据初始化。经过搜索各种博客,我发现Flask框架可以编写单独的命令用于初始化;同时我还结合网上的资料编写了解析MySQL格式的SQL脚本的代码,用于将SQL脚本转换为pymysql可以执行的语句。这样只需要用户在完成安装后执行初始化命令就可以自动完成数据库表和触发器的导入。
-
用户登陆
经过搜索文档之后,发现Flask框架自带了一个简单的登陆验证框架,可以直接使用。
-
相对目录问题
在打包完成后,程序无法识别到原有的相对路径。因为在打包后执行时,工作路径已经变成了别的不相关的路径了。这时候需要获取脚本的绝对路径,然后和原有的相对路径拼接就能解决这个问题
-
使用非root用户建立trigger时,出现
You do not have the SUPER privilege and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable报错。一种方法是,关掉binlog:在mysql的配置文件中增加一行
skip-logbin然后重启服务即可。因为这个项目也不可能用上主从复制,否则就不会是简单的导入两个脚本的问题了。另一种方法是,在配置文件里面增加它提示的设置项:
log_bin_trust_function_creators = 1